|
Ercole Colonese Consulenza di direzione e IT |
|
Home | Sviluppo software | Gestione servizi IT | Gestione progetti | Test e collaudi | Competenze relazionali | Servizi | Pubblicazioni | Chi sono | Info |
|
|
Metodi e tecniche per lo sviluppo del software |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Breve storia dell'Ingegneria del software
|
Che cosa sono? I "metodi" sono i concetti di base, le linee guida, le "tecniche" che l'ingegneria del software definisce dal punto di vista metodologico per la realizzazione del software. Senza conoscere i principi di base è difficile produrre del buon codice! Le categorie principali sono: "Metodi e tecniche" e "Tecnologie di sviluppo". Ciascuno elemento deve essere conosciuto dai professionisti del software ed indirizzato opportunamente a seconda delle necessità. Ignorarli significa produrre software di bassa qualità ed essere un professionista con molte lacune. Di seguito si riportano quelle considerate indispensabili per il bagaglio professionale dello sviluppatore.
Principi di base Si tratta dei principi di base da seguire nello sviluppo del software. Possono (e quindi devono) essere utilizzati per progettare, sviluppare e verificare codice con il livello di qualità atteso. E' opportuno, quindi, indirizzare le seguenti caratteristiche quando sviluppiamo del codice:
In sintesi, si tratta di una serie di caratteristiche che il software deve possedere per garantire qualità. In fase di analisi dei requisiti occorre individuare quali di queste siano critiche ed importanti ed indirizzarle opportunamente nella progettazione prima e nella realizzazione dopo. Ignorarle significa sviluppare codice con caratteristiche non adeguate alle necessità e, quindi, sviluppare un software "non di qualità". Maggiori dettagli sulle tecniche elencate sopra sono forniti nel documento dell'autore "Qualità del software" disponibile nella sezione "Pubblicazioni" di questo stesso sito. Tecniche di sviluppo Si tratta di metodi diversi che guidano il processo di sviluppo software, sia in fase di analisi e progettazione, sia in fase di codifica e testing. Tali metodiche dipendono principalmente dal diverso livello di formalismo seguito.
Le tecniche di sviluppo sono a loro volta supportate da modelli (o meta-modelli) e altri strumenti (Stili e Pattern). Si tratta di metodi potenti e tecniche complesse, specialmente quelle formali. Sono efficaci e supportano bene lo sviluppo di software di qualità in modo più semplice dei metodi tradizionali, specialmente i metodi agili. Ciascuno di essi rappresenta un vero e proprio mondo che necessita di studio, approfondimento, competenze specifiche, organizzazione dei gruppi di lavoro, consapevolezza del management. Non si forniscono quindi dettagli sui singoli metodi menzionati. Si consiglia di fare riferimento a pubblicazioni specifiche per ciascun argomento menzionato. Tecniche di verifica e validazione Si tratta di tecniche per la verifica e la validazione costante della qualità dei singoli prodotti di fase realizzati durante l'intero ciclo di sviluppo. Revisioni tecniche (ispezioni) La tecnica consiste nella revisione (ispezione) dei documenti prodotti nelle prime fasi del ciclo di sviluppo. Ha lo scopo di ricercare e rimuovere gli errori commessi ed evitare che si propaghino nelle fasi successive e quindi al codice finale (vedi "Teoria della propagazione degli errori nel software"). La revisione dei documenti verifica che essi siano completi, aderenti agli standard, coerenti, corretti e indirizzino tutti i requisiti, espliciti ed impliciti. I documenti da sottoporre a revisione sono quelli tecnici (documento dei requisiti, specifiche funzionali e tecniche, architettura applicativa, documenti di disegno di dettaglio), i piani (piano di progetto, di test, di qualità, di gestione della configurazione, di rilascio), i documenti di testing (casi di test, matrici di test, scenari di test), gli ambienti di test. E' bene sottoporre a revisione tecnica anche il codice, visto come un documento tecnico, in modo da verificare che esso sia scritto secondo gli standard di programmazione. Ovviamente devono essere definiti tali standard! E' bene predisporre opportune liste di verifica (checklist) per i vari aspetti del codice. La scelta dei moduli da sottoporre a ispezione può essere fatta a campione in modo da coprire tutti i programmatori e/o a copertura delle parti più complesse del programma. Testing E' l'esecuzione del codice secondo diversi livelli di aggregazione (test unitario, test d'integrazione, test di sistema, test d'accettazione). Ciascun tipo di test fa uso di particolari tecniche (white-box, black-box, error-guessing). A livello di integrazione dei singoli moduli in componenti le tecniche adoperate sono due (top-down e bottom-up). L'integrazione del codice utilizza la tecnica dei componenti "fantasma" (scaffolding) per sostituire quelli non ancora disponibili; questi componenti fantasma possono essere di due tipi (driver e stub); Maggiori dettagli sono forniti nel documento dell'autore "Collaudo del software" disponibile nella sezione "Pubblicazioni" di questo stesso sito. Tecniche di controllo della qualità Si tratta di tecniche per pianificare e controllare la qualità del software. Il software è di qualità quando "fa quello che deve fare" e "lo fa bene". In altre parole, il software è di qualità quando "sviluppa tutti i requisiti" ed è "privo di difetti". Entrambe le caratteristiche sono verificate tramite "revisioni tecniche interne" (ispezioni) e tramite l'esecuzione di test. Le due tecniche sono descritte come "Tecniche di verifica e validazione". Sappiamo bene come verificare l'aderenza ai requisiti, funzionali e qualitativi: tramite l'ispezione dei documenti tecnici e l'esecuzione di una serie di casi di test appositamente progettati. La presenza di difetti nel software rilasciato in esercizio è invece più difficile: i test rimuovono un gran numero di difetti ma ... quanti ne rimangono? Per il calcolo dei "difetti residui" si utilizzano tecniche statistiche. L'approccio è semplice dal punto di vista concettuale, meno quando lo si vuole applicare in un progetto reale. Il principio è semplice: "Il numero di errori residui in un software è dato dalla differenza tra il numero di errori immessi e di quelli rimossi". Il numero di errori immessi dagli sviluppatori nelle varie fasi del ciclo (Analisi, Progettazione, Sviluppo) dipende dai fattori descritti in precedenza (complessità, dimensioni, tecnologia, ciclo di vita, processo ecc.). Conoscere il numero di errori immessi durante lo sviluppo è difficile; il calcolo di tale numero è inoltre complicato dal fatto che molti errori si propagano generandone altri (vedi "Teoria della propagazione degli errori nel software" mostrata qui di seguito). Il numero di difetti rimossi dipende invece dall'efficacia delle ispezione dei documenti e dell'esecuzione dei test; tale numero e più facile da calcolare "contando" gli errori rilevati e corretti. Un'attenta analisi dei difetti rilevati durante il ciclo di sviluppo è importante per capire dove e come si può migliorare nel processo di sviluppo. Imparare dall'analisi degli errori rilevati è una tecnica di grande utilità. La classificazione ortogonale dei difetti (Orthogonal Defect Classification - ODC) è una tecnica consolidata di efficacia comprovata. La classificazione dei difetti permette di effettuare l'analisi di Pareto e poter intervenire in maniera mirata con azioni preventive per migliorare il processo di sviluppo e ridurre l'immissione degli errori. La tecnica dell'analisi causale conclude questo primo elenco di tecniche per il controllo della qualità del software. La rappresentazione delle cause identificate con un diagramma causa/effetto permette di rappresentare in forma grafica, e quindi meglio analizzabili, i principali problemi del progetto ed agire prontamente con azioni opportune. Le tecniche menzionate sono descritte brevemente qui di seguito, mentre dettagli maggiori sono forniti nel documento: "Ercole Colonese, Qualità del software." disponibile nell'area Pubblicazioni di questo stesso sito. Profilo di rimozione dei difetti (Defect Removal Profile) Il "Profilo di rimozione dei difetti" è una tecnica che prevede la registrazione dei difetti rilevati (e rimossi) durante l'intero ciclo di vita di sviluppo. Per ogni fase si registra il numero di errori rimossi: tramite le revisioni tecniche effettuate nelle fasi alte del ciclo sui documenti tecnici e tramite i test successivamente quando il codice è stato sviluppato. La tecnica si basa sull'osservazione generale che i difetti rilevati si distribuiscono secondo una curva a campana. La forma e l'altezza della curva dipende da vari fattori quali, ad esempio, la dimensione del prodotto, la tecnologia utilizzata, la complessità del software, il processo di sviluppo, la competenza delle persone. Solo la registrazione dei dati in un archivio dei progetti permette di avere a disposizione dati sufficienti per pianificare la curva di rimozione dei difetti di un prodotto da sviluppare. La forma e l'altezza della curva a consuntivo permette di estrapolare la difettosità residua del software rilasciato in esercizio. La costruzione di tali profili basati su di un numero statisticamente valido di progetti realizzati permette di produrre nuovi profili per nuovi progetti. Senza una base storica non è quindi possibile creare alcun nuovo profilo. Né si possono utilizzare profili realizzati da altre organizzazioni in quanto l'ambiente culturale dell'organizzazione software è uno degli elementi che influisce sul modello (e quindi non può essere importato da altri). Classificazione ortogonale dei difetti (Orthogonal Defect Classification-ODC) La tecnica consiste nella creazione di una tabella con la classificazione dei difetti rilevati durante le fasi del ciclo di sviluppo. Permette di individuare il profilo di immissione e quello di rimozione degli errori nel software. La valutazione è riferita al singolo progetto (dimensione, tecnologia adoperata, processo di sviluppo seguito, competenza delle persone, ecc.). In sintesi, la tecnica permette di proiettare la qualità finale del software sviluppato. La tabella che segue mostra un esempio di ODC.
Quali analisi si possano fare partendo dai dati contenuti nella tabella sono descritti in dettaglio nel documento menzionato sopra. Analisi di Pareto (Pareto's Analysis) La classificazione dei difetti rilevati in categorie ben precise consente l'analisi degli stessi e permette di evidenziare quali tipologie di errori sia bene indirizzare con opportune azioni preventive. L'analisi di Pareto permette infatti di evidenziare come l' 80% di errori rilevati sia ascrivibile ad un solo 20% di tipologie di errore. Per maggiori dettagli vedi pubblicazione menzionata sopra. Curva di rimozione dei difetti nel test (Testing Defect Removal) La tecnica permette di costruire una curva che mostra il "Livello di rimozione nel tempo dei difetti durante una fase di test". E' una tecnica che permette di controllare la capacità rimozione degli errori dal codice e di capire quando si giunge a "saturazione". Quando la curva tende ad un asintoto, che rappresenta il valore massimo di difetti rilevati, non sarà più possibile rimuovere altri errori proseguendo con i test. La tecnica si basa su di un principio tanto semplice quanto utile: "Durante una fase di rimozione, più errori si trovano e più se ne troveranno; meno errori si trovano e meno ne se troveranno". Si tratta di riportare il numero cumulativo di errori rilevati, giorno per giorno, durante l'esecuzione del test. Teoria della propagazione degli errori nel software (Software Defect Propagation) La teoria della propagazione degli errori nel software è stata presentata per la prima volta su di un articolo pubblicato dalla IBM System Scientific Institute nel lontano 1981 ed ancora valido nella sua formulazione. Secondo tale teoria in ogni fase del ciclo di vita si "inietta" un certo numero di errori. Alcuni di questi sono rimossi tramite attività di ispezione di testing. Altri, non rimossi, rimangono e si propagano nella fasi successive del ciclo di vita. Altri errori, in particolare, generano ulteriori errori. In definitiva, ogni fase del ciclo di vita è caratterizzata:
Avere consapevolezza di tale meccanismo evita di essere superficiali e sottovalutare il numero di errori residui nel software messo in esercizio. Analisi causale (Causal Analysis) L’analisi causale permette di migliorare la qualità dei progetti e le performance dell’organizzazione tramite un’attività preventiva. Elaborando l’esperienza maturata nei progetti ed analizzando i dati contenuti nell’archivio storico dei progetti è possibile risalire alle cause principali dei problemi rilevati e agire di conseguenza con azioni preventive che migliorino gli aspetti di fondo dell’organizzazione e, da questi, dei progetti e dei prodotti realizzati. L’analisi causale si effettua per ogni singolo “errore grave” (major error) riscontrato nel corso del progetto e permette di rilevare se la causa che ha generato il problema sia dovuta a:
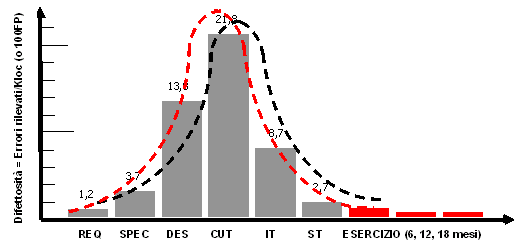
L’attività di analisi causale è condotta al termine di ogni progetto o, se necessario, al temine di una o più fasi di sviluppo particolarmente critiche per il proseguo del progetto. Una sessione di analisi non dovrà durare più di 5 o 6 ore analizzando nel complesso non più di 5 o 6 major error (spendendo cioè circa un’ora per ogni problema). Diagramma causa/effetto (Cause-Effect Diagram) La tecnica permette di rappresentare in forma grafica, e quindi più facilmente analizzabile, la catena causa/effetto dei difetti analizzati. La tecnica è anche detta "a lisca di pesce" per la sua particolare forma a spina. La linea orizzontale indica il problema (per esempio, il fallimento di un progetto), mentre le linee a spina indicano le cause principali (per esempio, pianificazione non adeguata, requisiti non chiari, ambito non definito, ecc.). Ciascuna linea a spina è, a sua volta, raggiunta da altre linee che ne indicano le cause (per esempio, cliente non disponibile, obiettivi non documentati e non concordati, stime eseguite da personale con scarsa esperienza, ecc.). Profilo di rimozione dei difetti (Defect Removal Profile) Il "Profilo di rimozione dei difetti" è una tecnica che prevede la registrazione dei difetti rilevati (e rimossi) durante l'intero ciclo di vita di sviluppo. Per ogni fase si registra il numero di errori rimossi: tramite le revisioni tecniche effettuate nelle fasi alte del ciclo sui documenti tecnici e tramite i test successivamente quando il codice è stato sviluppato. La Figura che segue mostra un andamento tipico della curva, mentre la Tabella successiva mostra la registrazione dei difetti.
Figura: Profilo della difettosità del software. Essa è costruita sulla base dei dati registrati durante le attività di rimozione degli errori nelle varie fasi, tramite ispezioni tecniche nelle fasi alte, tramite test nelle ultime fasi e direttamente dagli utenti in esercizio. La Tabella 1 mostra i valori registrati. Tabella 1. Registrazione dei difetti rimossi nelle fasi del ciclo di vita.
L'esperienza dice che aumentando l'efficacia della rimozione dei difetti nelle prime fasi del ciclo di vita si sposta la curva verso sinistra (curva in rosso) e diminuisce di conseguenza il numero di difetti rilevati nelle ultime fasi ed in particolare in esercizio. La lezione da imparare è la seguente: le ispezioni dei documenti tecnici nelle fasi di analisi e disegno riducono drasticamente il numero di errori residui nel software, tutto a beneficio delle fasi di test e di utilizzo del prodotto in esercizio. I vantaggi economici sono fin troppo evidenti. Costa molto di meno una ispezione tecnica che la correzione degli errori in una fase di test! Ricordiamoci della "teoria della propagazione degli errori nel software"2 ed il fattore di amplificazione (1:x). Propagazione degli errori nel software Secondo la teoria della propagazione degli errori nel software ogni fase del ciclo di vita è caratterizzata da:
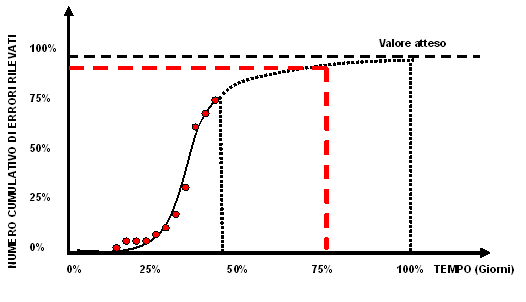
Figura: Propagazione degli errori nel software Si può intervenire su diversi fattori per migliorare la qualità del software. Si può ridurre il numero di errori immessi coinvolgendo sviluppatori con maggiore competenza, utilizzando standard, metodi e tecniche consolidate, ponendo particolare attenzione nello svolgimento del lavoro, ecc. Si può ridurre l'amplificazione degli errori (fattore 1:x) analizzando i dati statistici costruiti sulla base delle registrazioni effettuate in progetti simili (per esempio, ogni requisito omesso, mal interpretato e poco chiaro produce una catena di errori nelle fasi successive con un fattore 1:5). Si può migliorare l'efficienza percentuale di rilevazione degli errori in ciascuna fase migliorando l'efficacia delle ispezioni e revisioni tecniche (per esempio, istituendo ispezioni formali). Si può ridurre il numero di errori ereditati dalle fasi precedenti proprio con le tre tecniche descritte sopra. Avere consapevolezza di tale meccanismo evita di essere superficiali e sottovalutare il numero di errori residui nel software messo in esercizio. Maggiori dettagli si possono trovare in letteratura specializzata e in "Pubblicazioni disponibili" in questo stesso sito. Curva di rimozione dei difetti rilevati dal test (Testing Defect Removal) La tecnica permette di costruire una curva che mostra il "Livello di rimozione nel tempo dei difetti durante una fase di test". E' una tecnica che permette di controllare la capacità rimozione degli errori dal codice e di capire quando si giunge a "saturazione". Quando la curva tende ad un asintoto, che rappresenta il valore massimo di difetti rilevati, non sarà più possibile rimuovere altri errori proseguendo con i test. La tecnica si basa su di un principio tanto semplice quanto utile: "Il numero di errori che si troveranno nel software è proporzionale al numero di errori già trovati". La proporzione non è lineare ma è pur sempre Si tratta di riportare il numero cumulativo di errori rilevati, giorno per giorno, durante l'esecuzione del test. La figura di seguito mostra una tale curva basata sulla rilevazione giornaliera dei difetti e registrati, per esempio, in una tabella o in un tool apposito come può essere un foglio elettronico.
Figura: Curva di rimozione dei difetti rilevati in una fase di test Un modo semplice di costruire la curva è quello di registrare su di una tabella (esempio, un foglio elettronico) gli errori rilevati quotidianamente, calcolare il valore cumulativo giornaliero e costruire la curva di conseguenza. Nella figura si nota che, al 75% del tempo di test la curva tende già ad un valore di saturazione prossimo al 90%. La decisione di sospendere o proseguire i test non è fatta in base al numero di casi di test eseguiti ma alla capacità della curva di "saturare" (convergere verso il valore limite). Meta-metodi Si tratta di modelli non realizzati per guidare lo sviluppatore nella realizzazione del software ma per suggerire all'organizzazione come modellare i propri processi produttivi e gestionali in ottica di miglioramento continuo. Alcuni modelli di rilievo sono:
GQM Il metodo, presentato per la prima volta come oggetto di un articolo di ricerca di V.R. Basili, G.Caldiera e H.D. Rombach, si è poi molto diffuso diventando uno dei metodi più usati ed efficaci per la definizione e/o valutazione degli obiettivi relativi alla qualità del software. L’approccio GQM misura il raggiungimento degli obiettivi di un’organizzazione attraverso le misure che li caratterizzano dal punto di vista operativo. GQM combina buona parte dei moderni approcci alle misure in modo da incorporare processi, risorse e prodotti. E' quindi applicabile ad una vasta tipologia di ambienti ed è adottato da importanti organizzazioni (NASA, HP, Motorola, altri). L'associazione tra i vari elementi del modello si realizza attraverso un sistema di misurazione a tre livelli.
In estrema sintesi, il modello GQM identifica una serie di obiettivi di qualità oppure di produttività. Successivamente si derivano le domande che definiscono gli obiettivi nel modo più preciso possibile e si specificano le misure (i dati) da raccogliere per rispondere a queste domande. CMMI Il CMMI (Capability Maturity Model Integration) è un modello per il miglioramento dei processi produttivi e gestionali delle organizzazioni (nel nostro caso delle organizzazioni software). Esso definisce una scala di maturità delle organizzazioni in base alla loro capacità di operare secondo processi gestiti ed ottimizzati, di valutarne le inefficienze su base quantitativa e di introdurre cambiamenti ai processi per migliorare la qualità complessiva e l’efficienza dell’organizzazione. Alla base del modello (Livello di maturità 1) si collocano le organizzazioni che operano con approcci non codificati dove il successo è affidato agli sforzi individuali. Al massimo livello (Livello di maturità 5) si crea un circolo virtuoso nel quale alla misura dell’efficienza del processo corrisponde la capacità di imporre una “retroazione” correttiva od evolutiva attraverso la ridefinizione dei processi od in alcuni casi introducendo modifiche all’organizzazione. Maggiori dettagli sul modello e sua applicazione nelle organizzazioni software sono forniti in CMMI Improvement. Stili e pattern Il riuso di codice è un elemento importante ai fini della riduzione dei tempi e dei costi di sviluppo. Ma la vera sfida è quella del riuso della progettazione. Ciascun progettista di software sa molto bene quanto sia importante la propria esperienza. Egli usa metodi e tecniche non formalizzate per riprodurre gli schemi logici seguiti in precedenza. E' difficile formalizzare i pensieri e gli schemi logici. Ma la sfida è stata raccolta da molti ed il riuso della progettazione si è tradotta nel linguaggio tecnico nei design pattern. L'ingegneria del software definisce un design pattern come "una soluzione progettuale generale a un problema ricorrente". Non si tratta quindi di un codice riusabile ma di un modello conosciuto, e già utilizzato con successo, da applicare ad un nuovo problema, simile a quello precedente, in diverse situazioni durante la progettazione e lo sviluppo del software. Non è quindi un algoritmo, che invece risolve un problema computazionale, ma la soluzione ad un aspetto progettuale del software. I design pattern rappresentano un elemento importante per lo sviluppo dell'ingegneria del software, in particolare nell'ambito object-orieted. Il successo dei pattern è dovuto principalmente alla famosa "Banda dei quattro" (Gang of Four, GoF) composta da Erich Gamma, Richard Helm, Ralph Johnson e John Vissides. Un design pattern è composto generalmente dai seguenti elementi:
I design pattern sono generalmente classificati a seconda della tipologia o categoria di problemi che risolvono. Troviamo quindi pattern per i diversi settori d'industria (telecomunicazioni, banche ed assicurazioni, ecc.) e/o per categoria di problema risolto. Alcuni tra i principali sono: Pattern creazionali, mettono a disposizione degli sviluppatori i metodi con cui accedere alle funzionalità delle classi rese disponibili senza avere necessità di sapere come siano stare realizzate tecnicamente. Pattern strutturali, mettono a disposizione degli sviluppatori degli oggetti utilizzabili tramite interfacce adatte al loro utilizzo. Pattern comportamentali, forniscono soluzioni alle problematiche tipiche delle interazioni più comuni tra oggetti. Pattern architetturali, operano ad un livello più ampio del design, per esempio, a livello dell'architettura del sistema software descrivendone gli schemi di base per l'organizzazione dell'architettura stessa. Pattern di metodologia, identifica, descrive ed organizza le responsabilità dei vari oggetti o componenti che costituiscono l'architettura del sistema software; si tratta di un pattern metodologico di estrema importanza, basilare come appunto ribadito nel libro menzionato in fondo alla pagina. Pattern di concorrenza, si tratta di pattern sviluppati per mantenere il sincronismo dello stato dei dati quando ci siano più componenti che possano accedere in parallelo agli stessi dati. Altri tipi di pattern, si tratta di pattern che non agiscono a livello di disegno dei singoli componenti ma a livello più alto come, ad esempio, a livello di architettura, metodologia, ecc (vedi quelli elencati sopra). Per maggiori dettagli fare riferimento alle pubblicazioni specializzate (per esempio al libro dei quattro amici menzionati sopra: "Design Patterns: Elements of Reusable Object-Oriented Software", 1995). Linguaggi Si tratta dei comuni (ma per questo non banali) linguaggi utilizzati per lo sviluppo del software. Sono in grande numero e coprono le diverse esigenze applicative e tecnologiche. I linguaggi si sono profondamente evoluti nel tempo (prima, seconda, terza, quarta, quinta e sesta generazione) per meglio sfruttare le potenzialità delle nuove tecnologie. I linguaggi di programmazione sono quelli utilizzati per la produzione del codice; tra quelli più attuali ricordiamo: Java, C e C++, C#, Cobol, PL1, ecc. I linguaggi di mark-up sono utilizzati per descrivere informazioni e concetti in ambiente Internet e tecnologia Web. Tra quelli più conosciuti ricordiamo: HTML, XML, ecc. I linguaggi di modellazione sono utilizzati per tradurre in termini più formali quanto concordato con il cliente (requisiti e scenari di utilizzo) e l'architettura del sistema. Indirizza quindi i due domini: quello del problema e quello della soluzione. Il linguaggio di modellazione più conosciuto (ed utilizzato) è l'UML (Unified Modelling Language). I linguaggi domain-specific sono invece utilizzati per specifici ambienti o domini. Un esempio tipico è il linguaggio SQL per l'interrogazione delle base dati. Non si forniscono qui ulteriori dettagli in quanto ciascun linguaggio deve essere studiato in profondità per acquisire la competenza necessaria per scrivere del software. |
News/Articoli/Libri Collaudo e qualità del software Professione IT oggi in Italia ...
Collaborazioni
Indagine sull'utilizzo delle best practice Best practice del software proposte
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||